
Das Zielgruppenkonzept ist zentraler Bestandteil des Marketings. Besonders gilt das für traditionelle Personen-Zielsegmente, die anders gestaltet sind als die Lebenssituations-, Szenen- oder Milieu-Zielsegmente.
Ausgehen kann man dabei davon, dass die Kommunikation mit den Zielgruppen eine der wichtigsten Aufgaben des Unternehmens ist, um an Bekanntheit und Umsatz zu gewinnen.
Demzufolge wird unter einer Zielgruppe ganz allgemein die „Gesamtheit tatsächlicher oder potenzieller Personen, die mit einer bestimmten Marketingaktivität angesprochen werden sollen“ (Piepenbrock, D., 2015, S. 628), verstanden.
Somit ist „Zielgruppe“ ein relationaler Begriff. Es handelt sich nämlich nicht um eine innewohnende Eigenschaft einer Gruppe von Individuen, sondern das, was mit „Zielgruppe“ bezeichnet wird, stellt sich situativ, sozial und ökonomisch immer erst im Versuch her, eine solche zu bestimmen.
Wird das Konzept angewendet, ist es eine der wichtigsten Aufgaben, Zielgruppen zu finden beziehungsweise zu konstruieren. Ergebnis der Zielgruppenkonstruktion ist das Modell einer Zielgruppe, das ausgewählte Kunden eindeutig abbildet, sodass dabei die Beziehungen zwischen den Merkmalen der ausgewählten Kunden und der Struktur der Zielgruppe einander entsprechen (homomorphe Abbildung) (Klaus, G., 1968, S. 250ff.).
In diesem Fall repräsentieren Zielgruppen berechenbare Teilgruppen des Gesamtmarkts (Gerken, G., 1996, S. 14). Zielgruppen sind entweder im Vorhinein definierbar (zum Beispiel nach sozio-ökonomischen Kriterien, wie selbstständige Privatkunden, abhängig Beschäftigte und sonstige Privatkunden) oder deduktiv ableitbar nach bestimmten Kriterien der Marktsegmentierung (Schweiger, G., Diller, H., 2001, S. 1936). Gebräuchliche Segmente sind nach Ansicht des Managementberaters Mario Pufahl (Pufahl, M. 2003, S. 71):
- Kunden mit positiven oder negativen Deckungsbeiträgen;
- Kunden mit hohen oder geringen Umsätzen;
- Kunden mit hohen oder geringen Vertriebskosten;
- Kunden mit hohen oder geringen Ansprüchen;
- Kunden mit hohen oder geringen Scoring-Werten.
Um diese Segmente zu quantifizieren, wird in der Regel ein statisches Datenbild der Kunden verwendet. Die infrage kommenden Daten sind für einen bestimmten Zeitpunkt oder Zeitraum erhoben worden. Seltener wird ein dynamisches Datenbild verwendet, das heißt Panel-Daten oder Zeitreihendaten (Böhler, H., 2001, S. 1457).
Um Segmentierungsdaten zu verarbeiten, können sowohl Methoden des Data Mining oder des Big Data unter Einsatz von Machine oder Deep Learning als auch der statistischen multivariaten Analyse verwendet werden.
Hier finden Sie weitere Beiträge aus den Betriebswirtschaftlichen Blättern (BBL)
⇒ Infotipp: Setzen Sie auf diesen Link ein Bookmark – und Sie haben jederzeit einen Überblick über die Betriebswirtschaftlichen Blätter.
„Die Aufgabe an das Data Mining kann … durch die Maxime ,Finde heraus, was interessant ist!‘ umschrieben werden“ (Decker, R., Weiber, R., 2001, S. 255f.). Dies wird Bottom-up-Ansatz genannt. Hingegen wird an die multivariate Analyse „…die auf substanziell begründete Hypothesen gestützte Aufgabe gestellt ,Zeige, was im vorliegenden Kontext interessant ist!‘“ (Decker, R., Weiber, R., 2001, S. 255f.). Dafür wird der Begriff Top-down- Ansatz verwendet.
Aufgabenstellung klar definieren
Die zutreffend formulierte Zielgruppenbeschreibung ist für Produkt- und Preispolitik sowie Marktkommunikation sehr wichtig. Dabei muss zumindest folgende Voraussetzung erfüllt werden:
- Die Zielgruppen müssen untereinander trennscharf sein, das heißt sie dürfen (möglichst) keine Übereinstimmungen in ihrem charakteristischen Nachfrageverhalten haben.
Sind Zielgruppen nicht trennscharf, dann wird die Wirkleistung in der Ansprache der Zielgruppen „zerstreut“. Mengentheoretisch ausgedrückt heißt das: Die Grundmenge der Zielgruppen enthält nur „disjunkte“ Mengen. Mengen sind dann disjunkt, wenn es kein einziges Element (zum Beispiel die Entwicklung der zielgruppenspezifischen Kreditnachfrage) gibt, das in zwei oder mehr Mengen der Grundmenge enthalten ist.
Ob es gelungen ist, disjunkte Zielgruppen für den Vertrieb zu konstruieren, kann man folglich überprüfen, indem man das Nachfrageverhalten der einzelnen Zielgruppen miteinander vergleicht. Möglich ist das mithilfe eines qualitativen Vergleichs auf Ähnlichkeit, der aber nie frei von Unsicherheit ist, weil er stets subjektiv bleibt.
Eine Alternative dazu ist ein quantitativer Vergleich auf Grundlage einer statistischen Zeitreihenanalyse des Nachfrageverhaltens. Dabei werden die Zeitreihen des Nachfrageverhaltens der einzelnen Zielgruppen in eine multivariate Analyse einbezogen.
Annehmen lässt sich, dass Disjunktivität gegeben ist, wenn zwei Zeitreihen unterschiedlicher Zielgruppen eine negative lineare Korrelation oder eine irrelevante positive Korrelation (R< +0,71) aufweisen. Aber die Disjunktivität ist nicht gegeben, wenn:
- zwei Zeitreihen eine relevante positive lineare Korrelation (R>= +0,71) aufweisen und
- zwei Zeitreihen kointegriert sind. Kointegration bedeutet, dass zwei Zeitreihen gleichsam durch ein inneres Band in ihrer Entwicklung zusammengehalten werden. Genauer gesagt weisen sie einen gemeinsamen stochastischen Trend auf. Das ist ein Trend, der additiv verknüpft ist mit einer Variable des „Rauschens“ (Enders, W., 2004, S. 157ff.)[1]
Als Analysebeispiel dienen hier die beiden Zielgruppen „Handwerk“ und „inländische wirtschaftlich selbstständige Privatpersonen“ mit ihrer gesamten Kreditnachfrage, wie sie von der Deutschen Bundesbank definiert worden sind.
Zeitreihen-Beispiel
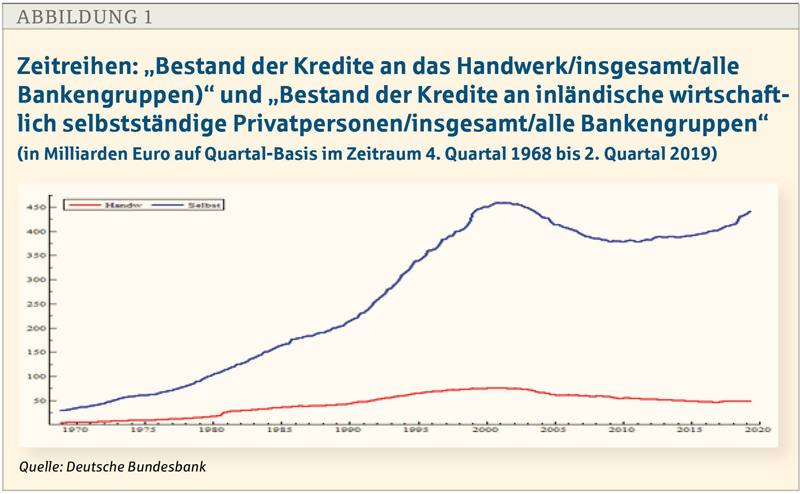
Abbildung 1 zeigt die gewählten Zeitreihen des Kreditbestands aller Banken in Deutschland für den Zeitraum viertes Quartal 1968 bis zweites Quartal 2019. Darin verläuft die Nachfrage nach Krediten der beiden Zielgruppen ähnlich.
Dementsprechend zeigen die beiden Zeitreihen eine starke positive lineare Korrelation mit dem Wert R= +0,9327, das heißt die erklärte gemeinsame Varianz beträgt 87 Prozent. Im Hinblick auf den ersten weiter oben genannten Prüfpunkt lässt sich feststellen, dass eine Korrelation R>= +0,71 gegeben ist. Bezogen auf die Kreditnachfrage beider Zielgruppen spricht dieser Sachverhalt gegen deren Disjunktivität.
Doch für sich allein genommen, reicht diese Feststellung nicht aus, um endgültig beurteilen zu können, ob Disjunktivität vorliegt oder nicht. Es könnte unter Umständen der Korrelation eine „spurious oder nonsense Regression“ zugrunde liegen (Pfaff, B., 2006, S. 40f.). Aus diesem Grund muss als nächstes noch eine mögliche Kointegration überprüft werden. Dazu wird ein State-Space-Model verwendet.
Kointegration überprüfen mit State-Space-Model
Um zu ermitteln, ob eine Kointegration vorliegt, wird hier eine multivariate Analyse mit den beiden als Beispiel gewählten Zeitreihen auf der Basis eines State-Space-Model mit Kalman-Filter (Durbin, J., Koopman, S.,J., 2001) durchgeführt.
Dabei handelt es sich um einen Spezialfall eines gemeinsamen Trends: glatte Trends mit gemeinsamen Slopes. Dieses ist wie folgt gestaltet: konstanter Level, stochastischer Slope, stochastische Saison – der Slope der Zeitreihe „Kredite an wirtschaftlich selbstständige Privatpersonen“ wird in Abhängigkeit zum Slope der Zeitreihe „Kredite an das Handwerk“ gesetzt.
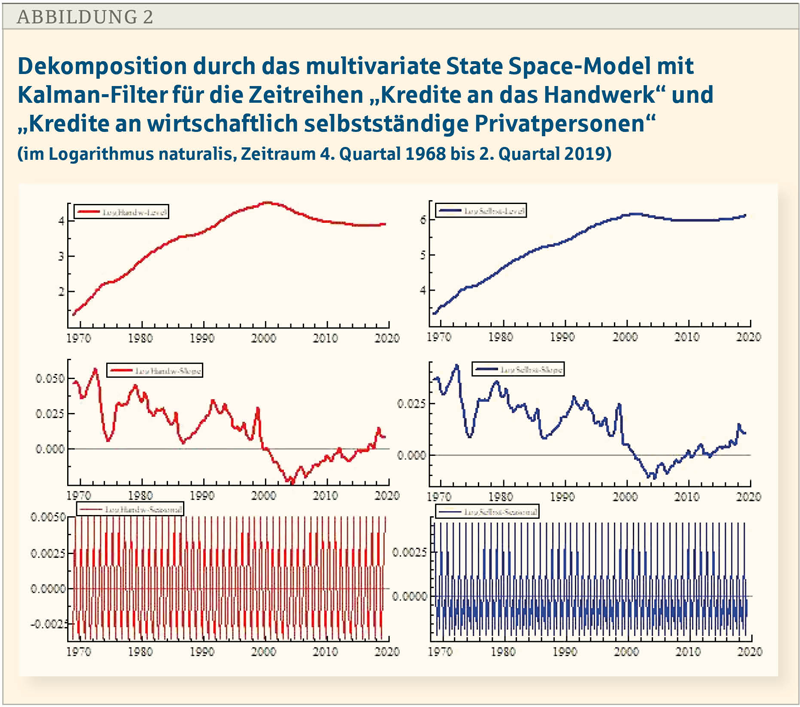
Für Analysezwecke werden die Werte der beiden Zeitreihen in den Logarithmus naturalis transformiert, um die Non-Linearität der Daten zu dämpfen. Die Ergebnisse der Dekomposition enthält Abbildung 2, wobei die Ergebnisse der Saison hier ignoriert werden, weil sie für die Prüfung irrelevant sind.
Nun ist ein weiterer Analyseschritt notwendig, der ein Data Drilling der anderen Art darstellt, mit dessen Hilfe eine „Zugangsschneise“ in das Innere der Datenstruktur geschlagen werden soll. Dort sind die Parameterwerte der Dekomposition eingelagert.
In diesem Falle heißt das, aus den Parameterwerten die Beziehungen zwischen den beiden Trends zu berechnen (siehe dazu: Koopman, S.J., Harvey, A.,C., Doornik, J.,A., Shepard, N., 2007, S. 93ff.). Das Ergebnis ist eine Beziehung zwischen den beiden Trends:

Folglich ist der Trend der Zeitreihe „Kredite an Selbstständige“ (µ2T) ein Multipel des anderen Trends (µ1T) mit einer deterministischen Trendkomponente. Daher sind nur die stochastischen Bewegungen in den Trends den beiden Trends gemeinsam.[2] Dies kann dahingehend gedeutet werden, dass die wirtschaftliche Tätigkeit von Handwerkern und Selbstständigen eher unterschiedlich strukturiert ist (zum Beispiel produzierendes Handwerk gegenüber dienstleistende freie Berufe).
Beide Zielgruppen sind jedoch der allgemeinen Konjunktur (verstanden als stochastischer Prozess mit zyklischer Komponente!) unterworfen, die letztlich ihre Kreditnachfrage prägt.
Mit Blick auf den zweiten weiter oben genannten Prüfpunkt kann also festgestellt werden, dass Kointegration vorliegt. Bezogen auf die Kreditnachfrage beider Zielgruppen spricht auch dieser Sachverhalt gegen die Disjunktivität der Zielgruppen.
Insgesamt lässt sich festhalten, dass beide der weiter oben genannten Voraussetzungen für Disjunktivität nicht erfüllt sind. Da eine Zielgruppe nicht aus homogenen Mitgliedern (zum Beispiel nur Selbstständige) bestehen muss, weil stets nur das Nachfrageverhalten ausschlaggebend ist, ist es möglich, aus beiden Mengen eine Vereinigungsmenge zu bilden. Beide Zeitreihen dürfen daher zu einer Zeitreihe addiert werden.
Im Folgenden bietet es sich an, für diese neue Zeitreihe ein State-Space-Model zu konstruieren (mit stochastischem Level, stochastischem Slope und stochastischer Saison). Mit dessen Hilfe kann dann eine Prognose für die anschließenden vier Quartale erstellt werden kann.
Darauf soll ein weiterer Schritt folgen, um die Probe zu machen, ob diese Prognose besser ausfällt als eine, die aus den beiden ursprünglichen Zeitreihen (auf Basis eines multivariaten State-Space-Model mit stochastischem Level, stochastischem Slope und stochastischer Saison) erstellt wird. Der begrenzte Platz für diesen Artikels zwingt dazu, die Darstellung der oben genannten Schritte auf das Ergebnis zu reduzieren.
Prognose der anschließenden Quartale

In einem ersten Schritt sollen nun die Ergebnisse der Prognose des State-Space-Model zur neuen Zeitreihe dargestellt werden (siehe Abb. 3). In einem zweiten Schritt wird die Probe darauf gemacht, ob es angebracht war, die Zielgruppen zu einer neuen Zeitreihe zu vereinigen. Deshalb werden jetzt die addierten Ergebnisse der einzelnen Prognosen aus den Zeitreihen des Handwerks und der Selbstständigen gezeigt (siehe Abb. 4).
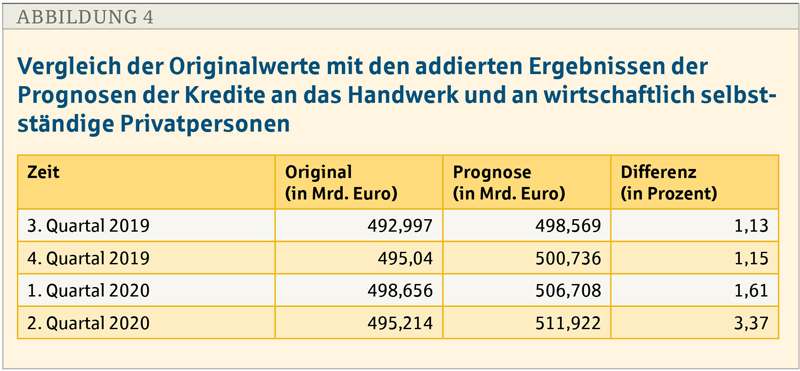
Aus der Zusammenschau der Abbildungen 3 und 4 wird ersichtlich, dass die Differenzen zwischen den Originalwerten und den Prognosewerten der neuen Zeitreihe geringer sind als zwischen den Originalwerten und den addierten Prognosewerten der Zeitreihen für die beiden Zielgruppen Handwerk und Selbstständige.
Somit ist die Prognosegenauigkeit der neuen Zeitreihe besser als diejenige der Zeitreihen für das Handwerk und die Selbstständigen. Es war also gerechtfertigt, die beiden nicht-disjunkten Zielgruppen zu einer neuen Zielgruppe zu vereinigen.
Fazit
Wenn Zielgruppen und Subzielgruppen konstruiert werden, muss auf die Trennschärfe zwischen den Zielgruppen geachtet werden. Das kann als einer der wichtigsten Qualitätsgrundsätze im Marketing gelten. Wird dieser Umstand missachtet, so erhält man nur sich irgendwie oder zufällig voneinander unterscheidende Zielgruppen, die sich nur ungezielt ansprechen lassen.
Ob die Zielgruppen trennscharf beziehungsweise disjunkt sind, kann – im Sinne der Qualitätssicherung für das Zielgruppenkonzept – beim Top-down-Ansatz mit Zeitreihen mithilfe einer statistischen Analyse auf lineare Korrelation und auf Kointegrität der zielgruppenspezifischen Zeitreihen geprüft werden.
Sollte sowohl eine relevante positive Korrelation als auch Kointegrität vorliegen, dann sind die Zielgruppen nicht disjunkt und können deshalb vereinigt werden. Die dadurch entstehende neue Zeitreihe zeichnet sich in der Regel durch eine bessere Prognosegenauigkeit aus.
Im weiter oben dargestellten Beispiel hat sich gezeigt, dass die Prägung der Zeitreihen für den Kreditbedarf des Handwerks und der Selbstständigen durch das Hintergrundrauschen der allgemeinen Wirtschaftskonjunktur wahrscheinlich ausschlaggebend für die Kointegration war.
Vermutlich ist auch die starke positive Korrelation der beiden Zeitreihen auf die Tatsache zurückzuführen, dass beide Zeitreihen dem Einfluss der allgemeinen Wirtschaftskonjunktur unterworfen sind. Das muss aber nicht immer der Fall sein, denn manche Wirtschaftsbereiche unterliegen Sonderkonjunkturen, die sie von anderen Wirtschaftsbereichen, die von der gewöhnlichen Konjunktur geprägt sind, unterscheiden.
Ob sich bei vorhandener Evidenz zwei oder mehr Zielgruppen zu einer übergreifenden Zielgruppe zusammengefasst lassen oder ob man einige der vorhandenen Zielgruppen neu „abmischen“ soll, hängt im Einzelfall von den Zielgruppenschwerpunkten der Verkaufsförderungsstrategie ab. Dazu zählt etwa die Frage, mit welcher kommunikativen Intensität und mit welchen Kommunikationsinhalten welche Zielgruppe bearbeitet werden soll (Bruhn, M., Homburg, Chr., 2004, S. 851).
Entscheidend dafür ist der den einzelnen Mitgliedern der Zielgruppen gemeinsame finanzielle Problemlösungsbedarf. Gelingt in diesem Sinne eine bessere Fokussierung der Zielgruppen, dann wird dadurch nicht nur eine Optimierung der Streupläne von Werbemitteln erreicht, indem unter anderem die Streuverluste deutlich reduziert werden (Diller, H., 2001, S. 1629), sondern auch der Verkaufserfolg gesteigert.
Literatur
- Brockwell, P.J., Davis, R.A., Introduction to Time Series and Forecasting, 2. Aufl., New York, 2002
- Bruhn, M., Homburg, Chr., Verkaufsförderungsstrategie, in: Bruhn, M., Homburg, Chr. (Hr.), Gabler Lexikon Marketing, 2. Aufl., Wiesbaden, 2004
- Böhler, H., Quasi-Experiment, in: Diller, H. [Hrsg.], Vahlens Großes Marketing Lexikon, Bd. 2, 2. Aufl., München, 2001
- Commandeur, J.J.F., Koopman, S.J., An Introduction to State Space Time Series Analysis, Oxford/New York, 2007
- Decker, R., Weiber, R., Data Mining (DM), in: Diller, H. [Hrsg.], Vahlens Großes Marketing Lexikon, Bd. 1, 2. Aufl., München, 2001
- Diller, H., Streuverluste, in: Diller, H. [Hrsg.], Vahlens Großes Marketing Lexikon, Bd. 2, 2. Aufl., München, 2001
- Durbin, J., Koopman, S.J., Time Series Analysis by State Space Models, Oxford/New York, 2001 Enders, W., Applied Econometric Time Series, Hoboken N.J., 2004
- Engle, R.F., Granger, C.W.J., Co-integration and error correction, representation, estimation and testing, Econometrica, Vol. 55, 1987, pp. 987-1007
- Gerken, G., Szenen statt Zielgruppen, in: Gerken, G., Merks, M. J. (Hr.), Szenen statt Zielgruppen, Frankfurt a.M., 1996
- Juselius, K., The Cointegrated VAR Model: Methodology and Applications, Oxford/New York, 2006 Klaus, G., Homomorphie, in: Klaus, G. (Hr.), Wörterbuch der Kybernetik, Berlin, 1968
- Koopman, S.J., Harvey, C., Doornik, J.A., Shephard, N., Structural Time Series Analyser and Modeller and Predictor – STAMP8, London, 2006
- Lütkepohl; H., Vector Autoregressive and Vector Error Correction Models, in: Lütlepohl, H., Krätzig, M. [Hrsg.], Applied Time Series Econometrics, Cambridge/New York, 2004
- Pfaff, B., Analysis of Integrated and Cointegrated Time Series with R, Heidelberg/New York, 2006 Piepenbrock, B. [Hrsg.], Zielgruppe, in: Piepenbrock (Hr.), Kompakt-Lexikon Wirtschaft, Bonn, 2015
- Pufahl, M., Vertriebscontrolling, Wiesbaden, 2003
- Schweiger, G., Diller, H., Zielgruppen, in: Diller, H. [Hrsg.], Vahlens Großes Marketing Lexikon, Bd. 2, 2. Aufl., München, 2001
Die Berechnungen für das lineare State-Space-Model mit Kalman-Filter sind mit dem Programmpaket OxMetrics 5.10 durchgeführt worden.
Autor
Rolf Kunstek war bis zu seiner Pensionierung Projektleiter Organisation bei der Kreissparkasse Göppingen.
Hier finden Sie weitere Beiträge aus den Betriebswirtschaftlichen Blättern (BBL)
⇒ Infotipp: Setzen Sie auf diesen Link ein Bookmark – und Sie haben jederzeit einen Überblick über die Betriebswirtschaftlichen Blätter.
[1] Statistisch gesagt, liegt dem Konzept der Kointegration die Idee zugrunde, dass zwei nicht-stationäre Zeitreihen sich „zusammen bewegen“. Das bedeutet, sie sind in dem Sinne miteinander verbunden, dass sie nur im Ausmaß einer stationären Wertesequenz – die eine Zeitreihe ergibt – differieren (Engle, R.F., Granger, C.W.J., 1987). Eine Zeitreihe {Xt, t=0, +/-1, …} ist dann stationär, wenn sie statistische Eigenschaften der „zeitverschobenen“ Zeitreihe {Xt+h, t=0, +/-1,…} für alle ganzen
Zahlen h hat (Brockwell, P.,J., Davis, A.D., 2002, S. 15).
[2] Ergänzend ist zu bemerken, dass die beiden Zeitreihen eine Kointegration der Ordnung (1, 1) mit dem Kointegrationsvektor (1, -1,47) aufweisen (Juselius, K., 2006, S. 79ff.). Kointegration der Ordnung (1, 1) heißt, dass die ersten Differenzen der Zeitreihenwerte gebildet werden müssen, dann kann aus ihrem Differieren eine Zeitreihe gebildet werden, die stationär ist. Die Signifikanz dieses Ergebnisses liegt sowohl beim Saikkonen&Lütkepohl-Test auf Kointegration [Lag 2, Rang 1, nur Constante, LR=9,06, pval= 0,0031] als auch beim Johansen-Trace-Test auf Kointegration [Lag 2, Rang 1, nur Constante, LR=15,84, pval=0,0019] auf dem 99-Prozent-Niveau der Sicherheit (Lütkepohl, H., 2004, S. 112ff.).


